Advanced Data Lakehouse: Olist Lakehouse 2.0
Databricks
Delta Lake
PySpark
This is the second version of the Olist project, now implementing modern data engineering practices in the Databricks Lakehouse with focus on declarative pipelines, governance, and incremental processing at scale.
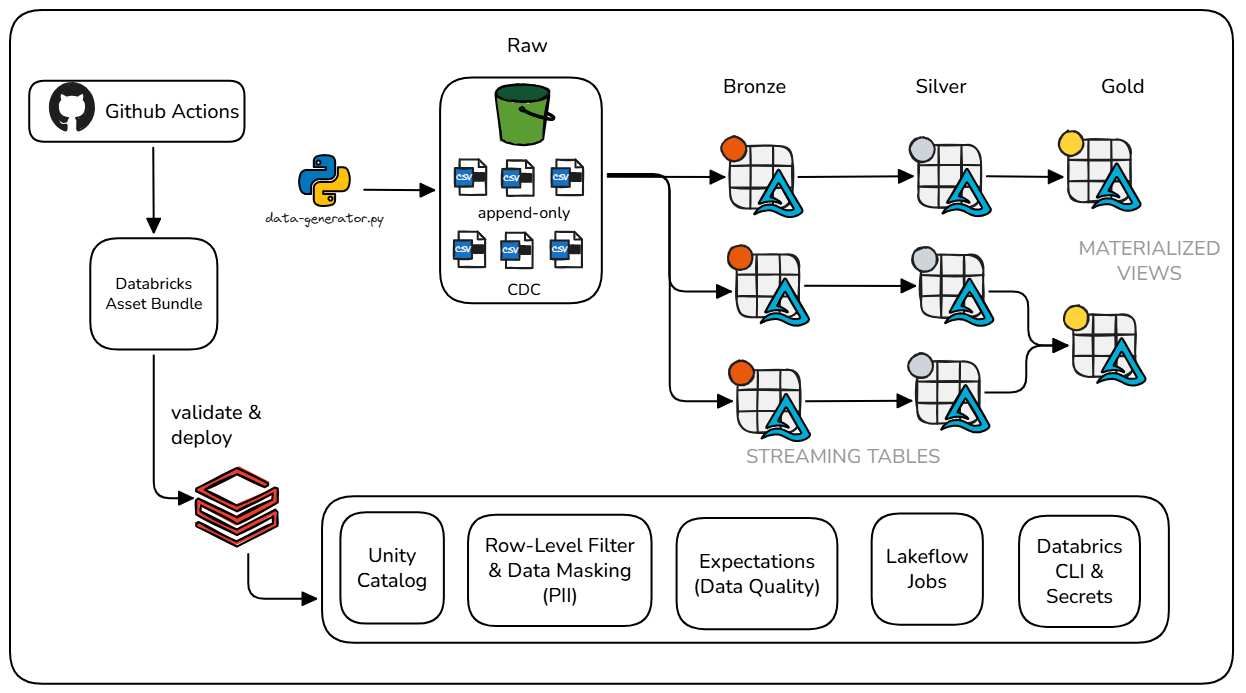
The architecture follows the Medallion pattern (Bronze, Silver, Gold) using Lakeflow Declarative Pipelines (formerly Delta Live Tables), with continuous ingestion via AutoLoader and change tracking with AUTO CDC for SCD Type 1 and Type 2 dimensions.
The project incorporates Data Quality with expectations at all layers, centralized governance with Unity Catalog, data lineage, and separation of pipelines for append-only transactional data and entities with historical changes.
All infrastructure and pipelines are deployed via Databricks Asset Bundles, with automated CI/CD, code validation, testing, and deployment across development, staging, and production environments.
Tools used
- Databricks Lakehouse & Delta Lake
- Lakeflow Declarative Pipelines (DLT)
- AutoLoader (incremental ingestion)
- AUTO CDC (SCD Type 1 and Type 2)
- Unity Catalog (governance and lineage)
- Databricks Asset Bundles (IaC)
- GitHub Actions (CI/CD)
- SQL, PySpark
Brazilian Congress Deputies Data Pipeline
Snowflake
dbt
Airflow
AWS S3
Python
Complete data pipeline focused on data engineering, with automated ingestion of public information from all federal deputies.
The data includes biography, mandates, expenses and parliamentary activity, extracted via official API.
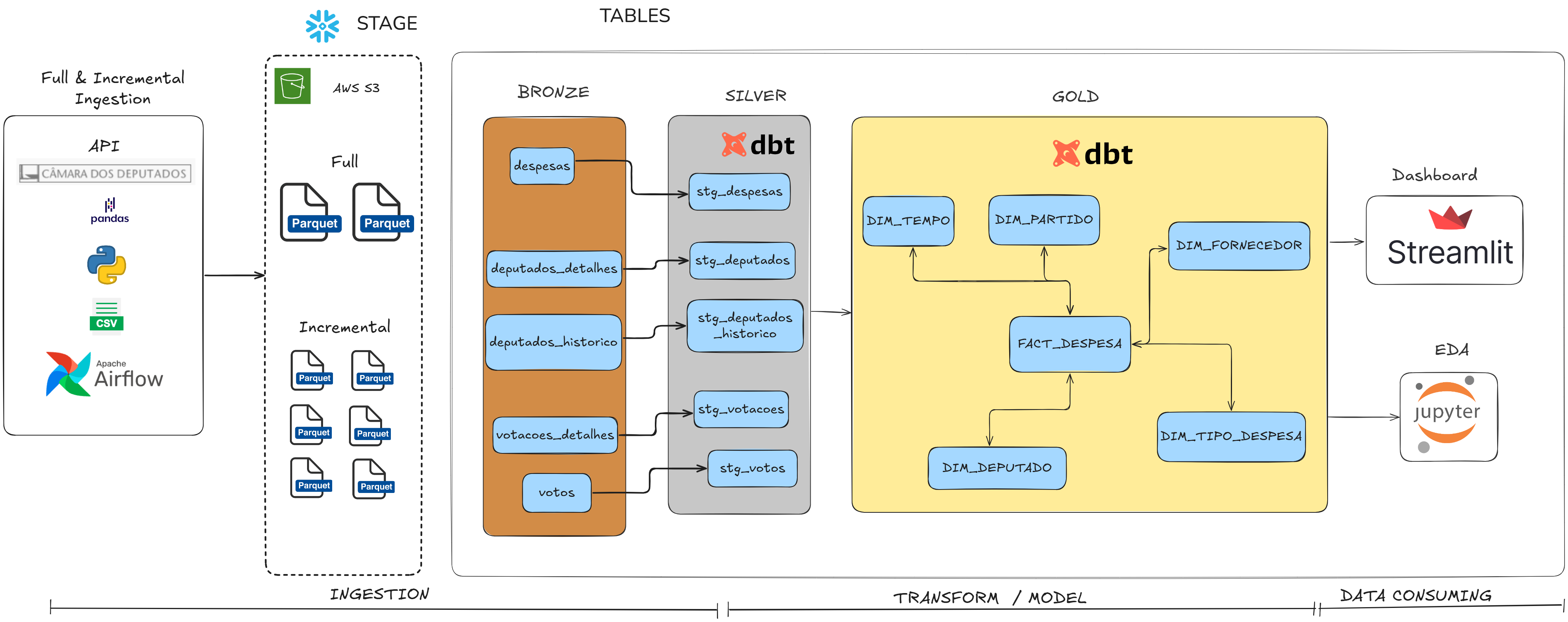
The architecture implements a modern ELT approach with Snowflake and dbt .
Daily incremental ingestion is orchestrated with Airflow and stored in S3 in Parquet format.
Transformations follow robust dimensional modeling patterns (SCD Type 2).
The project ensures end-to-end scalability, automation and data quality.
Tools used
- Python, Pandas and requests
- Apache Airflow
- Amazon S3 and SQS
- Snowflake, Snowpipe
- dbt Core
- Streamlit and Jupyter notebook
Data Lakehouse: Olist
Databricks
Delta Lake
Spark
Azure
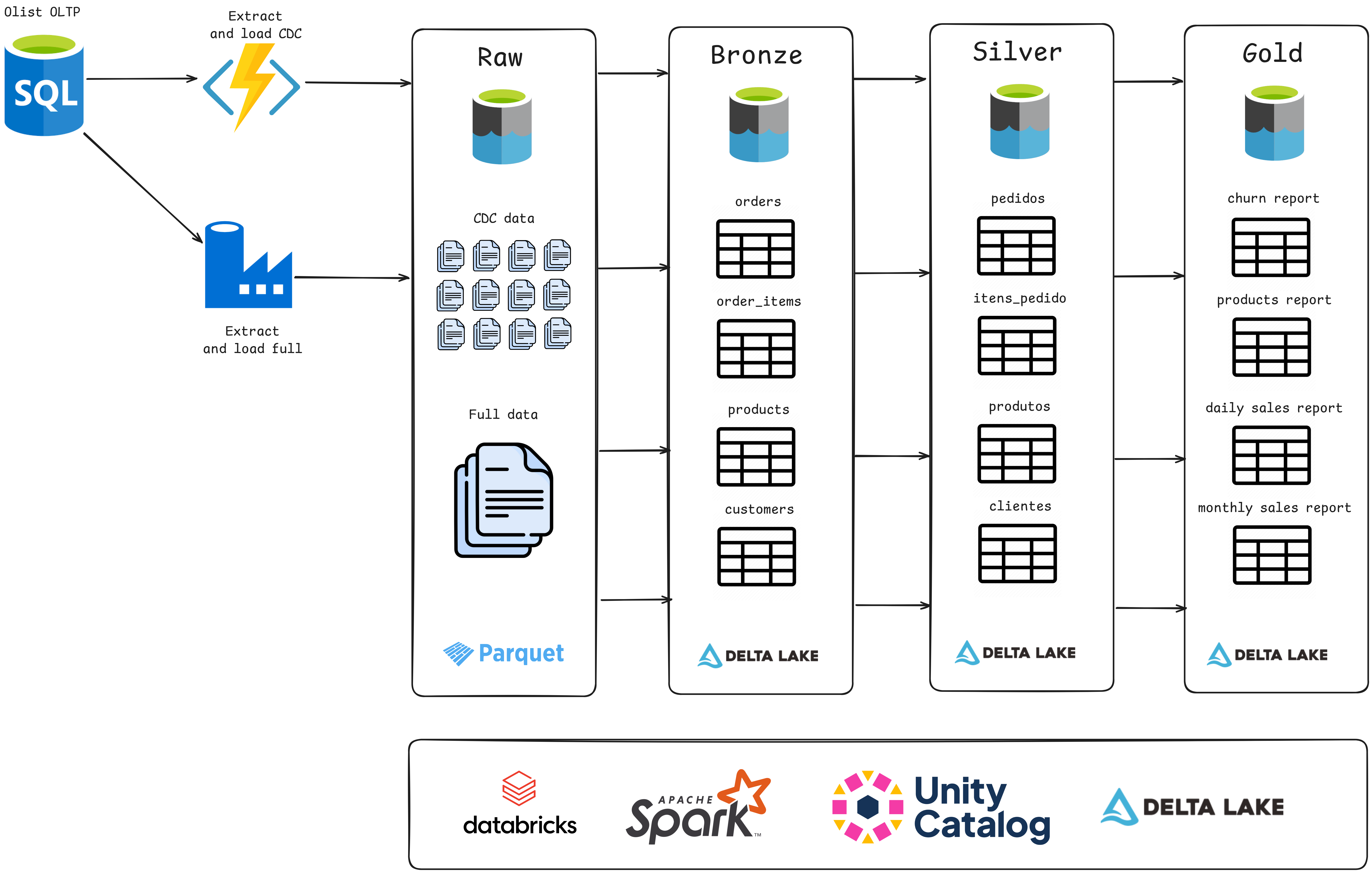
This project used the Databricks Data Lakehouse architecture to manage data in layers (Raw, Bronze, Silver, and Gold) and simulate ingestion scenarios with CDC (Change Data Capture). The data, from a Kaggle dataset, was enriched to create a complete pipeline, from ingestion to business analysis.
I implemented data governance with Unity Catalog, orchestration with Databricks Workflows, and continuous integration via GitHub Actions. The project consolidated skills in data pipelines, automation, and analysis with the Medallion architecture, optimizing the use of data for insights and analytical applications.
Tools used
- Pandas
- Git, GitHub, GitHub Actions
- Azure Blob Storage, Parquet
- Databricks, UnityCatalog
- Spark, Delta Lake
- Databricks Workflows
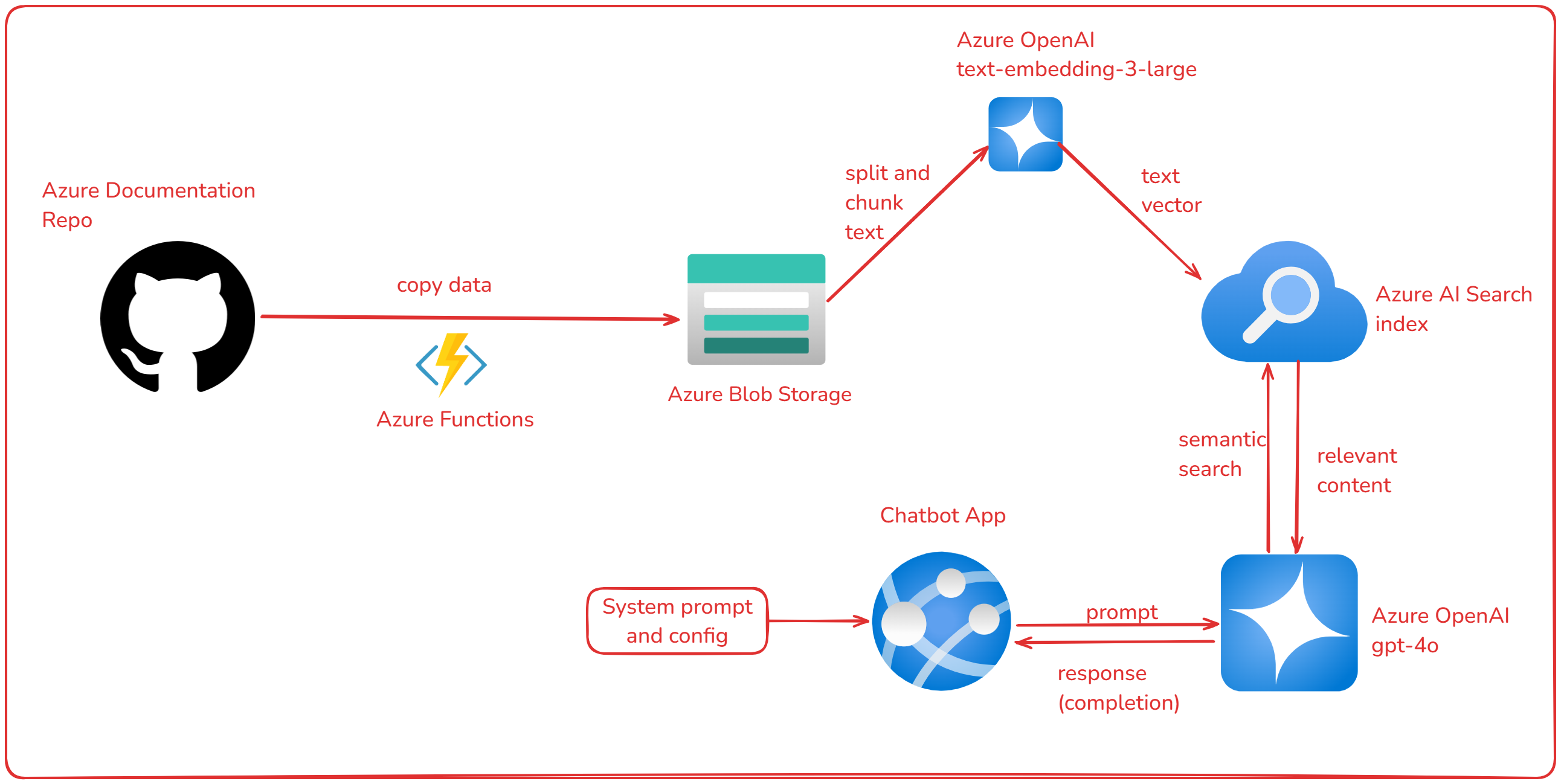
Chatbot with GPT-4 and Azure
GPT-4
RAG
Azure OpenAI
Azure AI Search
In this project, I explored Azure Artificial Intelligence tools to build a chatbot specialized in Azure using GPT-4. I copied the data from the Azure documentation on GitHub to the Storage Account, used Azure AI Search to perform embedding and indexing of the content, and Azure OpenAI to build the chatbot in an App on Azure. The goal is to provide accurate and contextualized answers about Azure services and functionalities.
Tools used
- Python
- Azure Blob Storage
- Azure AI Search
- Azure OpenAI
- Git, GitHub
- Bicep template (IaC)
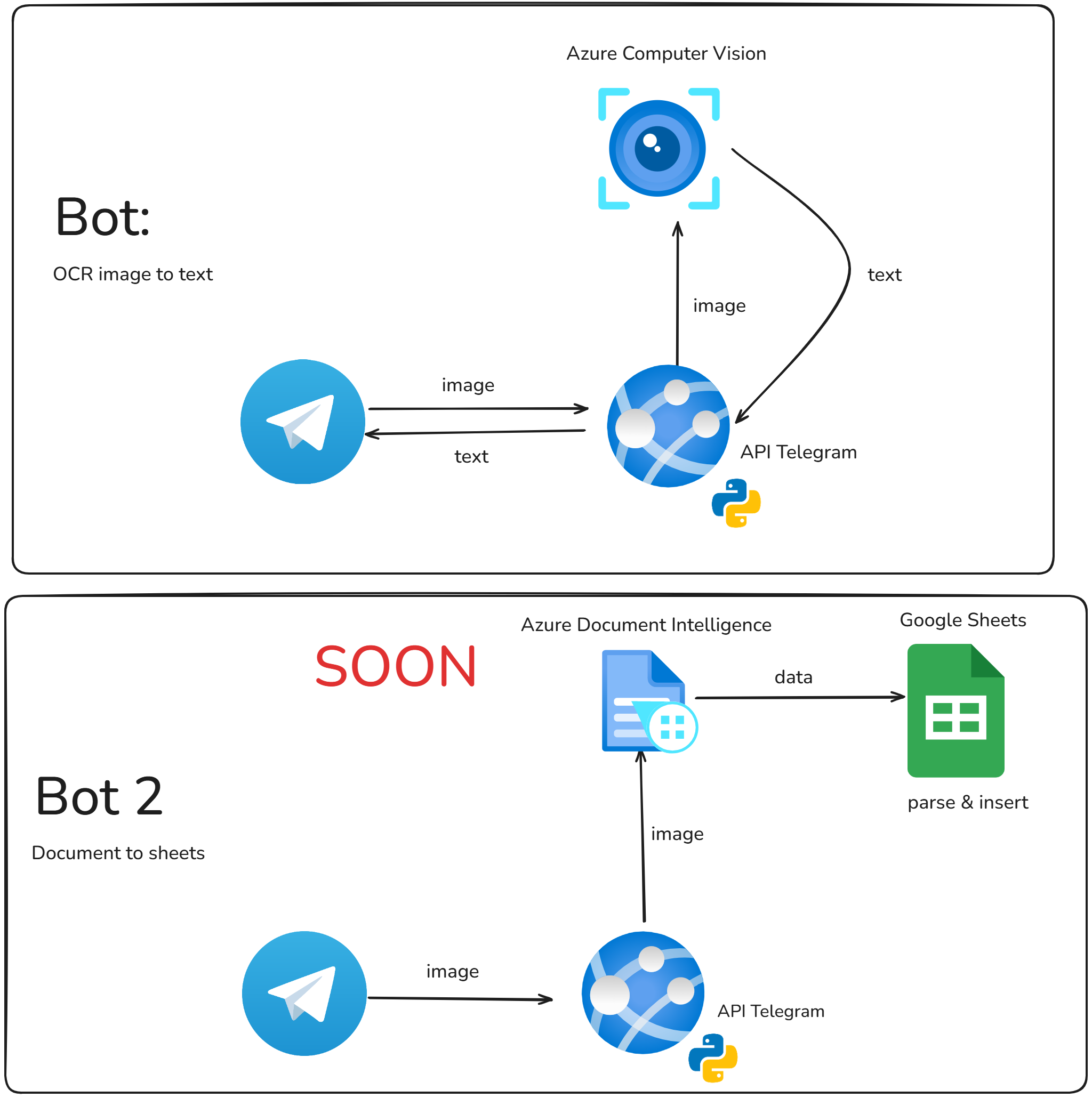
IN PROGRESS: Telegram Bot: Text Recognition (Computer Vision)
Computer Vision
Azure AI
Python
In this project, I explored Azure Artificial Intelligence tools for optical character recognition (OCR), such as Azure Computer Vision and Azure AI Document Intelligence. I used Python to develop a Telegram bot that processes images sent by the user, returning the extracted text and the confidence interval for each recognized word. I implemented dynamic settings in the bot, allowing adjustment of parameters such as the minimum confidence level to accept words and the application of pre-processing. This project demonstrates skills in API integration, image processing and the creation of interactive interfaces with bots.
Tools used
- Python
- Telegram API
- Azure Computer Vision
- Azure AI Document Intelligence
- Git, GitHub
- Bicep template (IaC)